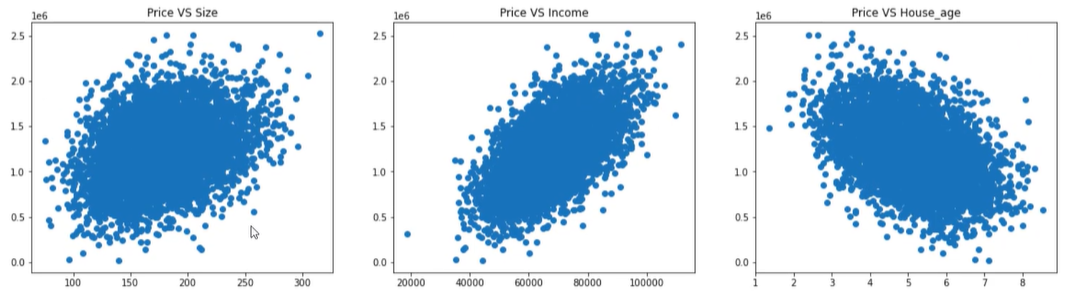
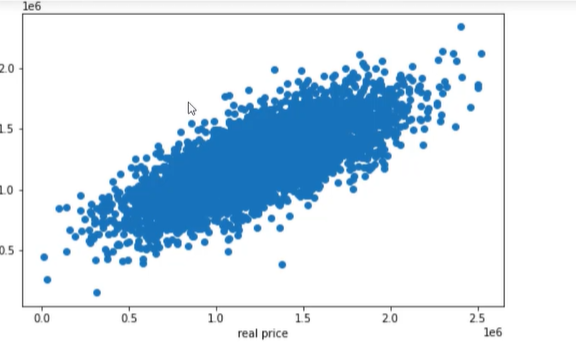
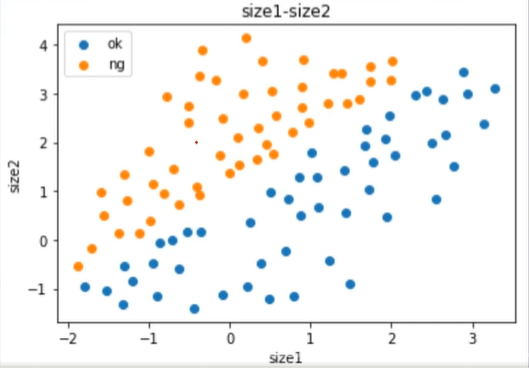
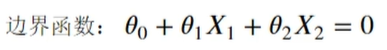在上一章博客中我们学习到了一些基本的机器学习的分类计算模型,接下来我们将进行更加深入的学习。
无监督学习:机器学习的一种方法,训练数据中不带标签,让机器自动寻找数据规律并完成任务。
特点:
- 数据不需要标签。
- 算法不受监督信息约束。
优点:
- 降低数据采集难度,极大程度扩充样本量。
- 可能发现新的数据规律、被忽略的重要信息。
聚类分析:把数据样本按照一定的方法分成不同的组别,这样让在同一个组别中的成员对象都有相似的一些属性。
K均值聚类:在样本数据空间中选取K个点作为中心,计算每个样本到各中心的距离,根据距离确定数据类别,是聚类算法中最为基础但也最为重要的算法。
核心流程:
- 基于要求,观察或经验确定聚类的个数K.
- 确定K个中心。
- 计算样本到各中心点距离。
- 根据距离确定各个样本点所属类别。
- 计算同类别样本的中心点,并将其设定为新的中心。
- 重复步骤3-5直到收敛(中心点不再变化)。
通过K均值聚类可以实现图像分割,图像分割就是把图像分成若干个特定的、具有独特性质的区域的技术,是由图像处理到图像分析的关键步骤。
KMeans实现数据聚类:
1 | import pandas as pd |
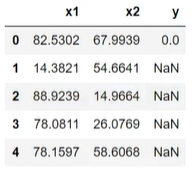
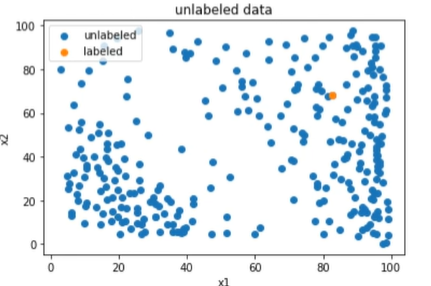
1 | #获取唯一一个有标签的数据点 |

1 | #x赋值 |
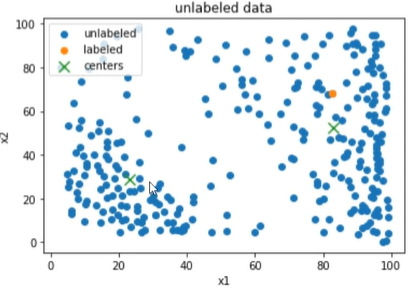
1 | #建立KMeans模型并训练 |
1 | #查看聚类中心 |
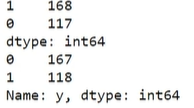
1 | #无监督聚类结果预测 |
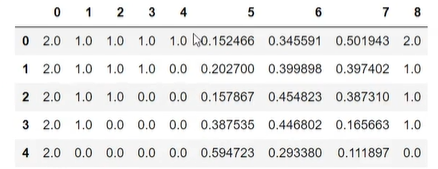
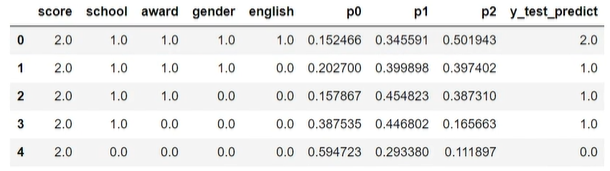
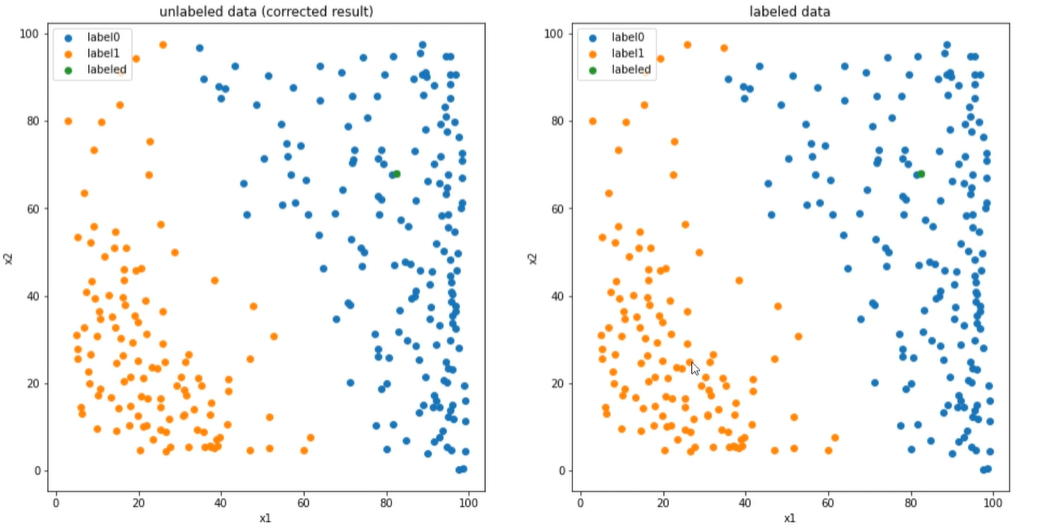
由测试数集可以看出,聚类预测的结果由较大的偏差,但也不难看出,可能在分析时,将1和0的分类有可能分反了,因此:
1 | #结果矫正 |
接下来,我们运用KNN算法进行建模并于之前的方法进行比较:
1 | #knn建模与训练 |
1 | #KMeans迭代一次的结果 |
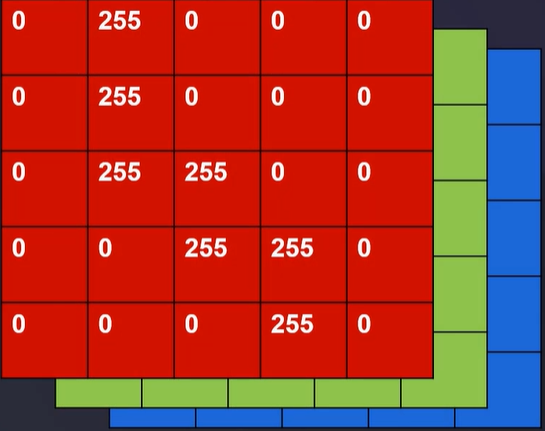
KMeans实现图像分割:
1 | #图像的加载与展示 |
1 | #维度存储 |
1 | #聚类结果预测 |

1 | #图像储存到本地 |

1 | #改变k值 |

由观察可知,k越小的时候,从一个层级到另一个层级过度的较快,轮廓较为清晰,k越大的时候,层级之间的过度较慢,轮廓较为模糊。
异常检测:根据输入数据,对不匹配预期模式的数据进行识别。
监督式异常检测:提前使用带“正常”与“异常”标签的数据对模型进行训练,机器基于训练好的模型判断新数据是否为异常数据。
无监督式异常检测:通过寻找与其他数据最不匹配的实例来检测出未标记测试数据的异常。
数据降维:在一定的限定条件下,按照一定的规则,尽可能的保留原始数据集重要信息的同时,降低数据集特征的个数。
随着特征数量越来越多,为了避免过拟合,对样本数量的需求会以指数速度增长。
数据降维最常用的方法:主成分分析(PCA),
也称主分量分析,按照一定规则把数据变换到一个新的坐标系统中,使得任何数据投影后尽可能可以分开(新数据尽可能不相关,分布方差最大化)。
计算过程:
- 数据预处理(数据分布标准化:u=0,o=1)。
- 计算协方差矩阵特征向量、及数据在各特征向量投影后的方差。
- 根据需求(任务指定或方差比例)确定降维维度k。
- 选取k维特征向量,计算数据在其形成空间的投影。
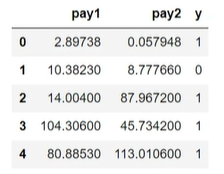
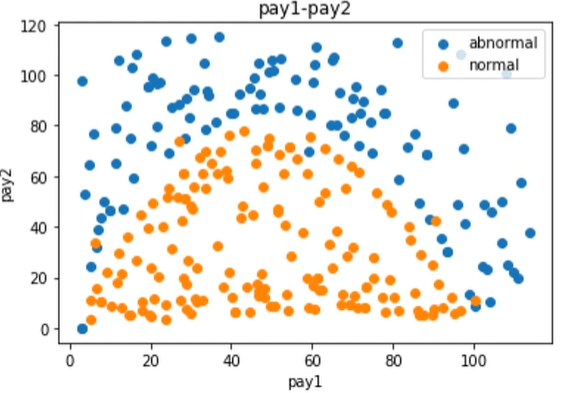
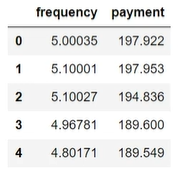
异常消费行为检测:
1 | #数据加载 |
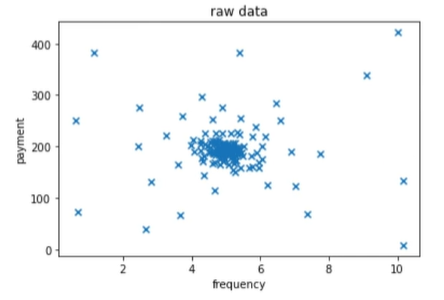
1 | #数据可视化 |
1 | #赋值 |
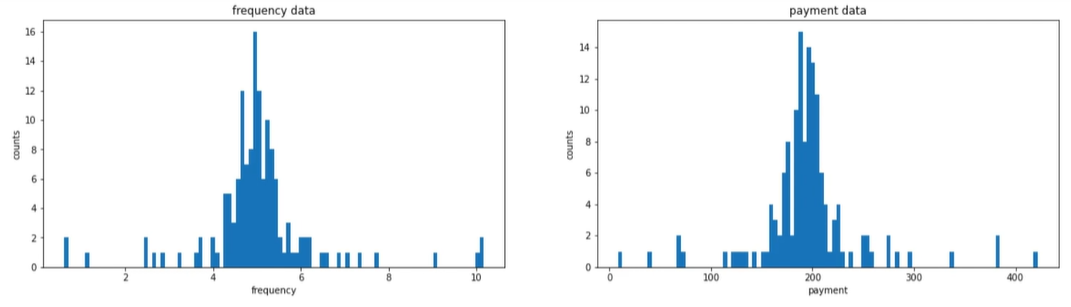
1 | #计算平均值u,以及标准差sigma |
1 | #原始数据的高斯分布概率密度函数的可视化 |
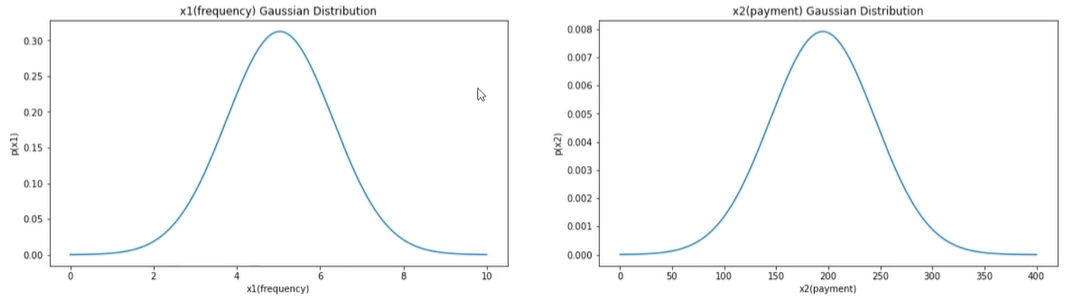
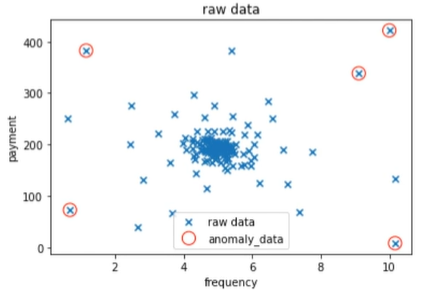
1 | #建立异常检测模型 |
当contamination=0.2时:
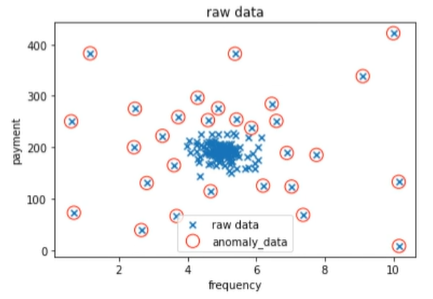
由此可见,当阈值增大时,检测出的异常数据的比例也因此增大。
PCA+逻辑回归预测检查者是否患糖尿病
1 | #数据加载 |
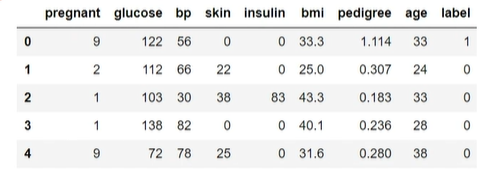
1 | #赋值 |
1 | #数据标准化 |
1 | #可视化 |
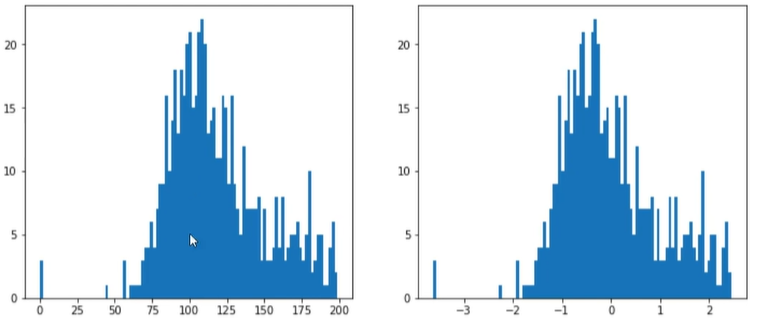
1 | #pca分析 |
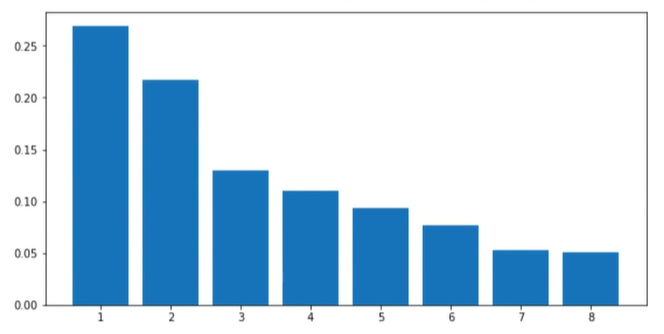
1 | #可视化方差比例 |
1 | #数据降维到2维 |
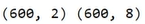
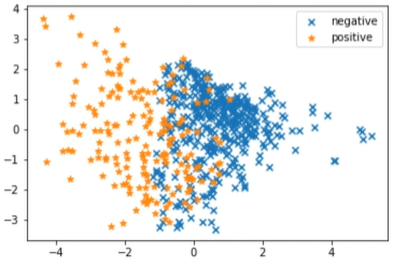
由此可见,通过pca将原本八维的数据降维成了二维。
1 | #降维数据的可视化 |
1 | #降维后的模型建立与训练 |